Cuffless BP - example¶
Import Libraries and Database¶
! pip install wfdb
! pip install neurokit2
import neurokit2 as nk2
import wfdb
import numpy as np
from scipy import signal
import matplotlib.pyplot as plt
# MIMIC info
database_name = 'mimic4wdb/0.1.0' # The name of the MIMIC IV Waveform Database on Physionet
# Segment for analysis
segment_names = ['83404654_0005', '82924339_0007', '84248019_0005',
'82439920_0004', '82800131_0002', '84304393_0001',
'89464742_0001', '88958796_0004', '88995377_0001',
'85230771_0004', '86643930_0004', '81250824_0005',
'87706224_0003', '83058614_0005', '82803505_0017',
'88574629_0001', '87867111_0012', '84560969_0001',
'87562386_0001', '88685937_0001', '86120311_0001',
'89866183_0014', '89068160_0002', '86380383_0001',
'85078610_0008', '87702634_0007', '84686667_0002',
'84802706_0002', '81811182_0004', '84421559_0005',
'88221516_0007', '80057524_0005', '84209926_0018',
'83959636_0010', '89989722_0016', '89225487_0007',
'84391267_0001', '80889556_0002', '85250558_0011',
'84567505_0005', '85814172_0007', '88884866_0005',
'80497954_0012', '80666640_0014', '84939605_0004',
'82141753_0018', '86874920_0014', '84505262_0010',
'86288257_0001', '89699401_0001', '88537698_0013',
'83958172_0001']
segment_dirs = ['mimic4wdb/0.1.0/waves/p100/p10020306/83404654',
'mimic4wdb/0.1.0/waves/p101/p10126957/82924339',
'mimic4wdb/0.1.0/waves/p102/p10209410/84248019',
'mimic4wdb/0.1.0/waves/p109/p10952189/82439920',
'mimic4wdb/0.1.0/waves/p111/p11109975/82800131',
'mimic4wdb/0.1.0/waves/p113/p11392990/84304393',
'mimic4wdb/0.1.0/waves/p121/p12168037/89464742',
'mimic4wdb/0.1.0/waves/p121/p12173569/88958796',
'mimic4wdb/0.1.0/waves/p121/p12188288/88995377', 'mimic4wdb/0.1.0/waves/p128/p12872596/85230771', 'mimic4wdb/0.1.0/waves/p129/p12933208/86643930', 'mimic4wdb/0.1.0/waves/p130/p13016481/81250824', 'mimic4wdb/0.1.0/waves/p132/p13240081/87706224', 'mimic4wdb/0.1.0/waves/p136/p13624686/83058614', 'mimic4wdb/0.1.0/waves/p137/p13791821/82803505', 'mimic4wdb/0.1.0/waves/p141/p14191565/88574629', 'mimic4wdb/0.1.0/waves/p142/p14285792/87867111', 'mimic4wdb/0.1.0/waves/p143/p14356077/84560969', 'mimic4wdb/0.1.0/waves/p143/p14363499/87562386', 'mimic4wdb/0.1.0/waves/p146/p14695840/88685937', 'mimic4wdb/0.1.0/waves/p149/p14931547/86120311', 'mimic4wdb/0.1.0/waves/p151/p15174162/89866183', 'mimic4wdb/0.1.0/waves/p153/p15312343/89068160', 'mimic4wdb/0.1.0/waves/p153/p15342703/86380383', 'mimic4wdb/0.1.0/waves/p155/p15552902/85078610', 'mimic4wdb/0.1.0/waves/p156/p15649186/87702634', 'mimic4wdb/0.1.0/waves/p158/p15857793/84686667', 'mimic4wdb/0.1.0/waves/p158/p15865327/84802706', 'mimic4wdb/0.1.0/waves/p158/p15896656/81811182', 'mimic4wdb/0.1.0/waves/p159/p15920699/84421559', 'mimic4wdb/0.1.0/waves/p160/p16034243/88221516', 'mimic4wdb/0.1.0/waves/p165/p16566444/80057524', 'mimic4wdb/0.1.0/waves/p166/p16644640/84209926', 'mimic4wdb/0.1.0/waves/p167/p16709726/83959636', 'mimic4wdb/0.1.0/waves/p167/p16715341/89989722', 'mimic4wdb/0.1.0/waves/p168/p16818396/89225487', 'mimic4wdb/0.1.0/waves/p170/p17032851/84391267', 'mimic4wdb/0.1.0/waves/p172/p17229504/80889556', 'mimic4wdb/0.1.0/waves/p173/p17301721/85250558', 'mimic4wdb/0.1.0/waves/p173/p17325001/84567505', 'mimic4wdb/0.1.0/waves/p174/p17490822/85814172', 'mimic4wdb/0.1.0/waves/p177/p17738824/88884866', 'mimic4wdb/0.1.0/waves/p177/p17744715/80497954', 'mimic4wdb/0.1.0/waves/p179/p17957832/80666640', 'mimic4wdb/0.1.0/waves/p180/p18080257/84939605', 'mimic4wdb/0.1.0/waves/p181/p18109577/82141753', 'mimic4wdb/0.1.0/waves/p183/p18324626/86874920', 'mimic4wdb/0.1.0/waves/p187/p18742074/84505262', 'mimic4wdb/0.1.0/waves/p188/p18824975/86288257', 'mimic4wdb/0.1.0/waves/p191/p19126489/89699401', 'mimic4wdb/0.1.0/waves/p193/p19313794/88537698', 'mimic4wdb/0.1.0/waves/p196/p19619764/83958172']
Key Functions¶
All functions are derived from the original PPG work done by Elisa Mejía Mejía.
start_seconds = 100 # time since the start of the segment at which to begin extracting data
no_seconds_to_load = 60
rel_segment_no = 3
rel_segment_name = segment_names[rel_segment_no]
rel_segment_dir = segment_dirs[rel_segment_no]
sig, meta = wfdb.rdsamp(record_name=rel_segment_name,
pn_dir=rel_segment_dir,
sampfrom=0, sampto=100)
fs = round(meta['fs'])
sampfrom = fs*start_seconds
sampto = fs*(start_seconds+no_seconds_to_load)
ppg, fields = wfdb.rdsamp(record_name=rel_segment_name,
pn_dir=rel_segment_dir,
sampfrom=sampfrom, sampto=sampto,
channel_names = ['Pleth'])
ppg = ppg.squeeze()
Find peaks¶
def get_peaks(raw, fs):
ppg_clean = nk2.ppg_clean(raw, sampling_rate=fs)
peaks = nk2.ppg_findpeaks(ppg_clean, method="bishop", show=False)
return peaks['PPG_Peaks'][0]
peaks = get_peaks(ppg, fs)
plt.figure(figsize=(20,5))
plt.plot(ppg)
heights = ppg[peaks]
plt.scatter(peaks, heights, marker='o', color='green')
<matplotlib.collections.PathCollection at 0x7faf84d7a820>
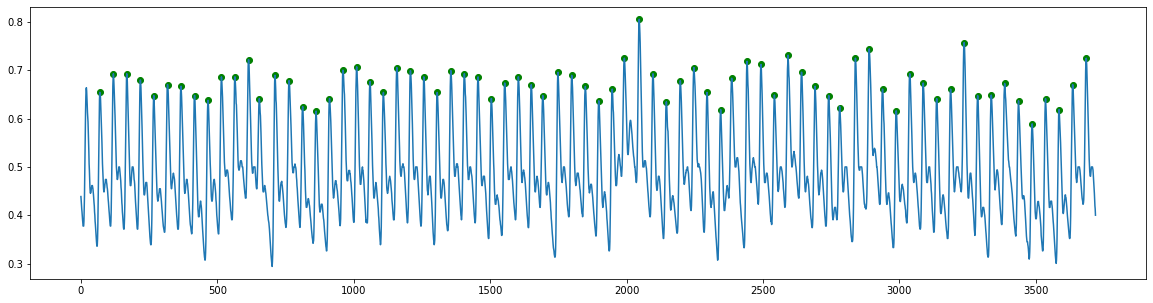
Find Onsets¶
def get_onsets(ppg, pks, fs):
ons = np.empty(0)
for i in range(len(pks) - 1):
start = pks[i]
stop = pks[i + 1]
ibi = ppg[start:stop]
aux_ons = np.argmin(ibi)
# aux_ons, = np.where(ibi == np.min(ibi))
ind_ons = aux_ons.astype(int)
ons = np.append(ons, ind_ons + start)
ons = ons.astype(int)
return ons
peaks = get_peaks(ppg, fs)
onsets = get_onsets(ppg, peaks, fs)
plt.figure(figsize=(20,5))
plt.plot(ppg)
heights_peaks = ppg[peaks]
heights_onsets = ppg[onsets]
plt.scatter(peaks, heights_peaks, marker='o', color='green')
plt.scatter(onsets, heights_onsets, marker='o', color='red')
<matplotlib.collections.PathCollection at 0x7faf86106670>
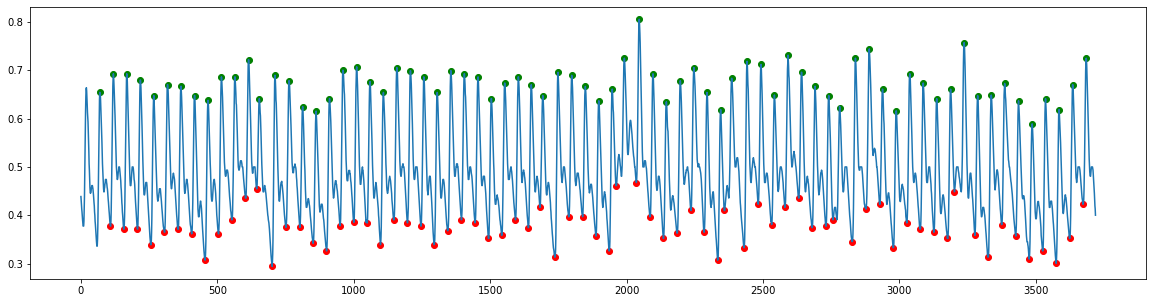
Find Diastolic peak and Dicrotic notch¶
Differentiation Demo¶
import scipy.signal as sp
ppg_seg = ppg[0:200]
seg_peaks = get_peaks(ppg_seg, fs)
seg_onset = get_onsets(ppg_seg, seg_peaks, fs)
d1x = sp.savgol_filter(ppg_seg, 9, 5, deriv = 1)
d2x = sp.savgol_filter(ppg_seg, 9, 5, deriv = 2)
d3x = sp.savgol_filter(ppg_seg, 9, 5, deriv = 3)
fig, axs = plt.subplots(3, figsize=(20,20))
axs[0].plot(ppg_seg)
axs[0].scatter(seg_onset, ppg_seg[seg_onset], color='red')
axs[0].set_ylabel('PPG')
axs[1].plot(d1x)
axs[1].set_ylabel('1st derivative of PPG')
axs[2].plot(d2x)
axs[2].scatter(seg_onset, d2x[seg_onset], color='red')
axs[2].set_ylabel('2nd derivative of PPG')
Text(0, 0.5, '2nd derivative of PPG')
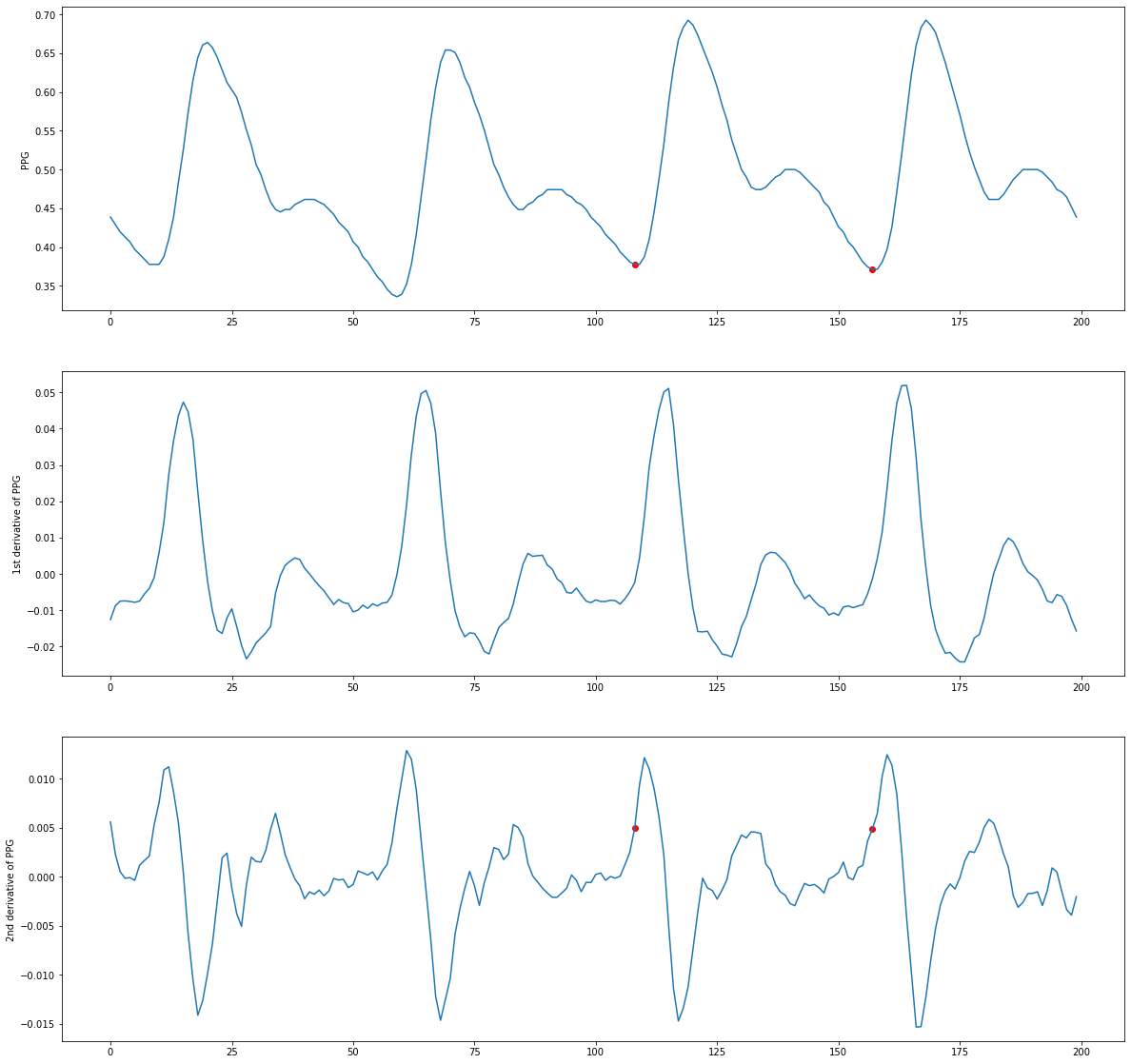
Actual Function¶
import scipy.signal as sp
def get_dia_dic(ppg, pks, ons, fs):
d1x = sp.savgol_filter(ppg, 9, 5, deriv = 1)
d2x = sp.savgol_filter(ppg, 9, 5, deriv = 2)
d3x = sp.savgol_filter(ppg, 9, 5, deriv = 3)
dia = np.empty(0)
dic = np.empty(0)
for i in range(len(ons) - 1):
start = ons[i]
stop = ons[i + 1]
ind_pks = np.intersect1d(np.where(pks < stop), np.where(pks > start))
if len(ind_pks) != 0:
ind_pks = ind_pks[0]
ind_pks = pks[ind_pks]
ibi_portion = ppg[ind_pks:stop]
ibi_2d_portion = d2x[ind_pks:stop]
aux_dic, _ = sp.find_peaks(ibi_2d_portion)
aux_dic = aux_dic.astype(int)
aux_dia, _ = sp.find_peaks(-ibi_2d_portion)
aux_dia = aux_dia.astype(int)
if len(aux_dic) != 0:
ind_max, = np.where(ibi_2d_portion[aux_dic] == np.max(ibi_2d_portion[aux_dic]))
aux_dic_max = aux_dic[ind_max]
if len(aux_dia) != 0:
nearest = aux_dia - aux_dic_max
aux_dic = aux_dic_max
dic = np.append(dic, (aux_dic + ind_pks).astype(int))
ind_dia, = np.where(nearest > 0)
aux_dia = aux_dia[ind_dia]
nearest = nearest[ind_dia]
if len(nearest) != 0:
ind_nearest, = np.where(nearest == np.min(nearest))
aux_dia = aux_dia[ind_nearest]
dia = np.append(dia, (aux_dia + ind_pks).astype(int))
else:
dic = np.append(dic, (aux_dic_max + ind_pks).astype(int))
break
dia = dia.astype(int)
dic = dic.astype(int)
return dia, dic
ppg_seg = ppg[0:200]
seg_peaks = get_peaks(ppg_seg, fs)
seg_onset = get_onsets(ppg_seg, seg_peaks, fs)
seg_dia, seg_dic = get_dia_dic(ppg_seg, seg_peaks, seg_onset, fs)
plt.figure(figsize=(10,5))
plt.plot(ppg_seg)
plt.ylabel('PPG')
plt.scatter(seg_onset, ppg_seg[seg_onset], color='red',label='Onsets')
plt.scatter(seg_dia, ppg_seg[seg_dia], color='green',label='Diastolic Peaks')
plt.scatter(seg_dic, ppg_seg[seg_dic], color='purple',label='Dicrotic Notches')
plt.legend()
<matplotlib.legend.Legend at 0x7faf871d0e20>
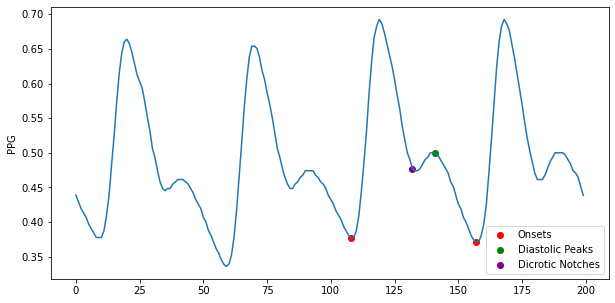
Run BP Estimation¶
def get_fids(ppg, fs):
pks = get_peaks(ppg, fs)
ons = get_onsets(ppg, pks, fs)
dia, dic = get_dia_dic(ppg, pks, ons, fs)
return pks, ons, dia, dic
def get_signal(rel_segment_no, label, start_sec, len_sec):
if label == 'ppg':
chan = 'Pleth'
elif label == 'bp':
chan = 'ABP'
rel_segment_name = segment_names[rel_segment_no]
rel_segment_dir = segment_dirs[rel_segment_no]
sig, meta = wfdb.rdsamp(record_name=rel_segment_name,
pn_dir=rel_segment_dir,
sampfrom=0, sampto=100)
fs = round(meta['fs'])
sampfrom = fs*start_sec
sampto = fs*(start_sec + len_sec)
req_sig, fields = wfdb.rdsamp(record_name=rel_segment_name,
pn_dir=rel_segment_dir,
sampfrom=sampfrom, sampto=sampto,
channel_names = [chan])
req_sig = req_sig.squeeze()
return req_sig, fs
def get_less_closest(array, value):
array = np.array(array)
index, arr = np.argwhere(array<value), array[array<value]
idx = (np.abs(arr - value)).argmin()
return array[index[idx]]
def remove_nan(sig):
nan_ind= np.argwhere(np.isnan(sig))
return np.delete(sig, nan_ind)
Test Example¶
dias = [467,505,617,679,747,825,923,982,1065,1147,1225,1302,1378,1460,1540,1616,1703,1776,1853,1933,2010,2096,2179,2250,2331,2407,2487,2563,2642,2716,2800,2875,2961,3031,3111,3190,3292,3342,3418,3496,3576]
pks = [326,407,487,568,648,728,809,889,968,1047,1127,1206,1285,1363,1443,1521,1601,1680,1758,1838,1917,1996,2075,2154,2233,2312,2390,2469,2547,2625,2704,2781,2860,2938,3016,3093,3170,3247,3326,3404,3482,3559,3636]
peaks = [get_less_closest(pks, dia)[0] for dia in dias]
delta_t = np.subtract(peaks, dias)
delta_t
array([-60, -18, -49, -31, -19, -16, -34, -14, -18, -20, -19, -17, -15,
-17, -19, -15, -23, -18, -15, -16, -14, -21, -25, -17, -19, -17,
-18, -16, -17, -12, -19, -15, -23, -15, -18, -20, -45, -16, -14,
-14, -17])
Get delta_t and bp example¶
ppg, fs = get_signal(3, 'ppg', 100, 60)
ppg = remove_nan(ppg)
pks, ons, dias, dics = get_fids(ppg, fs)
corrs_peaks = [get_less_closest(pks, dia)[0] for dia in dias]
delta_t = np.subtract(dias, corrs_peaks)/fs
bp, fs = get_signal(3, 'bp', 100, 60)
bp = remove_nan(bp)
pks = get_peaks(bp, fs)
ons = get_onsets(bp, pks, fs)
sbp = np.median(bp[pks])
dbp = np.median(bp[ons])
print(np.mean(delta_t), sbp, dbp)
0.3548387096774194 118.84375 64.0625
Get training set¶
len(segment_names)
52
import pandas as pd
# train_set = pd.DataFrame(np.nan,
# columns = ['id',
# 'pk_to_dia', 'pk_to_dic',
# 'on_to_pk', 'on_to_dia', 'on_to_dic',
# 'peak_len',
# 'peak_h', 'dia_h', 'dic_h', 'on_h',
# 'sbp', 'dbp'],
# index = list(range(0,100)))
# train_set['id'] = train_set['id'].astype(str)
# train_set.shape
# intv = 60
# i = 0
# for start in range(40, 800, 60):
# for no in range(40, 52):
# ppg, fs = get_signal(no, 'ppg', start, intv)
# ppg = remove_nan(ppg)
# pks, ons, dias, dics = get_fids(ppg, fs)
# on_pks = [get_less_closest(ons, pk)[0] for pk in pks[1:]]
# on_to_p = np.subtract(pks[1:], on_pks)/fs
# on_dia = [get_less_closest(ons, dia)[0] for dia in dias]
# on_to_dia = np.subtract(dias, on_dia)/fs
# on_dic = [get_less_closest(ons, dic)[0] for dic in dics]
# on_to_dic = np.subtract(dics, on_dic)/fs
# dia_pks = [get_less_closest(pks, dia)[0] for dia in dias]
# p_to_dia = np.subtract(dias, dia_pks)/fs
# dic_pks = [get_less_closest(pks, dic)[0] for dic in dics]
# p_to_dic = np.subtract(dics, dic_pks)/fs
# bp, fs = get_signal(no, 'bp', start, intv)
# bp = remove_nan(bp)
# pks = get_peaks(bp, fs)
# ons = get_onsets(bp, pks, fs)
# sbp = np.median(bp[pks])
# dbp = np.median(bp[ons])
# train_set.at[i, 'id'] = str(no)+'-'+str(start)+'-'+str(intv)
# train_set.at[i, 'on_to_pk'] = np.mean(on_to_p)
# train_set.at[i, 'on_to_dia'] = np.mean(on_to_dia)
# train_set.at[i, 'on_to_dic'] = np.mean(on_to_dic)
# train_set.at[i, 'pk_to_dia'] = np.mean(p_to_dia)
# train_set.at[i, 'pk_to_dic'] = np.mean(p_to_dic)
# train_set.at[i, 'peak_h'] = np.mean(ppg[pks])
# train_set.at[i, 'dia_h'] = np.mean(ppg[dias])
# train_set.at[i, 'dic_h'] = np.mean(ppg[dics])
# train_set.at[i, 'on_h'] = np.mean(ppg[ons])
# train_set.at[i, 'peak_len'] = np.mean(np.diff(pks)/fs)
# train_set.at[i, 'sbp'] = sbp
# train_set.at[i, 'dbp'] = dbp
# i += 1
# train_set.to_csv('train_res.csv')
Run Linear Regression¶
! wget https://raw.githubusercontent.com/kellydingzx/ppg-bp-data/main/train.csv
! wget https://raw.githubusercontent.com/kellydingzx/ppg-bp-data/main/test.csv
--2023-03-14 22:53:41-- https://raw.githubusercontent.com/kellydingzx/ppg-bp-data/main/train.csv
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 81643 (80K) [text/plain]
Saving to: ‘train.csv’
train.csv 100%[===================>] 79.73K --.-KB/s in 0.005s
2023-03-14 22:53:41 (15.1 MB/s) - ‘train.csv’ saved [81643/81643]
--2023-03-14 22:53:42-- https://raw.githubusercontent.com/kellydingzx/ppg-bp-data/main/test.csv
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.109.133, 185.199.110.133, 185.199.108.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 27342 (27K) [text/plain]
Saving to: ‘test.csv’
test.csv 100%[===================>] 26.70K --.-KB/s in 0.001s
2023-03-14 22:53:42 (50.9 MB/s) - ‘test.csv’ saved [27342/27342]
import pandas as pd
train_set = pd.read_csv('train.csv').set_index('Unnamed: 0')
train_set = train_set.dropna()
test_set = pd.read_csv('test.csv').set_index('Unnamed: 0')
test_set = test_set.dropna()
train_set = train_set.drop(train_set[train_set['sbp']>220].index)
test_set = test_set.drop(test_set[test_set['sbp']>220].index)
train_set.shape, test_set.shape
((364, 13), (68, 13))
features = ['pk_to_dia', 'pk_to_dic',
'on_to_pk', 'on_to_dia', 'on_to_dic',
'peak_len',
'peak_h', 'dia_h', 'dic_h', 'on_h']
X, X_test = train_set[features].to_numpy(), test_set[features].to_numpy()
y, y_test = train_set['dbp'].to_numpy(), test_set['dbp'].to_numpy()
import numpy as np
from sklearn.linear_model import LinearRegression
reg = LinearRegression().fit(X, y)
print(reg.score(X, y))
print(reg.coef_, reg.intercept_)
y_pred = reg.predict(X_test)
0.07020956884995677
[ 17.27915979 -3.77602219 3.43481116 7.73166082 -13.32352116
-5.41141461 -18.12401551 -30.69878586 44.17869563 49.58030356] 36.07810821002502
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test, y_pred)
271.9106456602938
from sklearn.ensemble import RandomForestRegressor
regr = RandomForestRegressor(max_depth=100, random_state=0)
regr.fit(X, y)
print(regr.score(X, y))
pred = regr.predict(X_test)
0.9104779254812161
mean_squared_error(y_test, pred)
266.31520622271375